什么是shading?
在光栅化模块中,我们于抗锯齿的SSAA方法种提到了着色(shading)这一词。着色是一个很重要的环节,它负责计算出颜色(光栅化只是填充像素格,换句话说是负责转移颜色到屏幕),换句话说着色就是计算出每个采样像素点的颜色是多少。着色计算要考虑的因素通常有:光照、纹理、着色频率(着色单位)等。
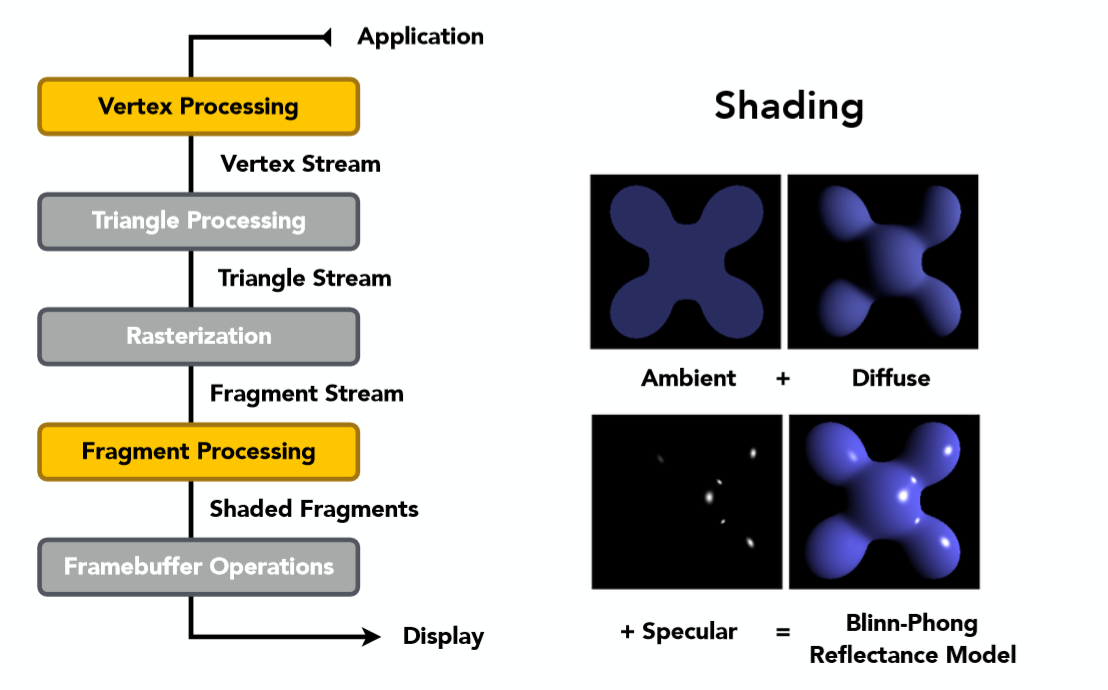
Blinn-phong 反射模型(reflection model)
Blinn-Phong光照模型,又称为Blinn-phong反射模型(Blinn–Phong reflection model)或者 phong修正模型(modified Phong reflection model),是由 Jim Blinn于 1977 年在文章中对传统 phong光照模型基础上进行修改提出的。它是一个经验模型,并不完全符合真实世界中的光照现象,但由于实现起来简单方便,并且计算速度和得到的效果都还不错,因此在早期被广泛的使用。
它将进入摄像机的光线分为三个部分,每个部分使用一种方法来计算它的贡献度,这三个部分分别是**环境光(Ambient)、漫反射(Diffuse)和高光反射(Specular)**。如下图:

在计算之前,我们先定义一些基本的向量,因为只表示方向,默认它们都为单位向量:
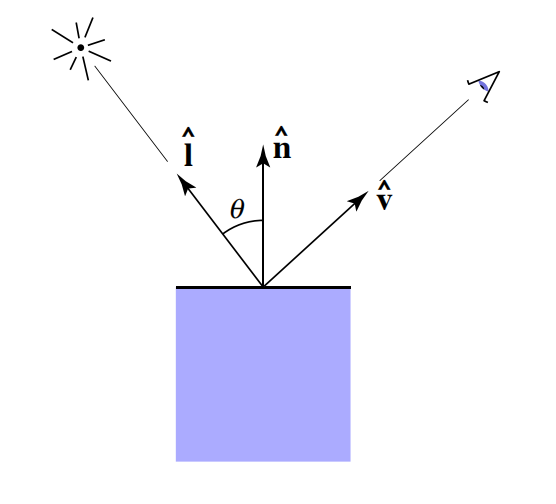
Viewer direction,观察方向,使用v表示Surface normal,法线方向,使用n表示Light direction,光线方向,使用l(小写的L)表示
漫反射(Diffuse reflection)
首先搞清什么是漫反射:是投射在粗糙表面上的光向各个方向反射的现象。当一束平行的入射光线射到粗糙的表面时,表面会把光线向着四面八方反射,所以入射线虽然互相平行,由于各点的法线方向不一致,造成反射光线向不同的方向无规则地反射,这种反射称之为“漫反射”或“漫射”。正是因为反射是完全随机的,因此可以认为漫反射光在任何反射方向上的分布都是一样的,如下图所示:
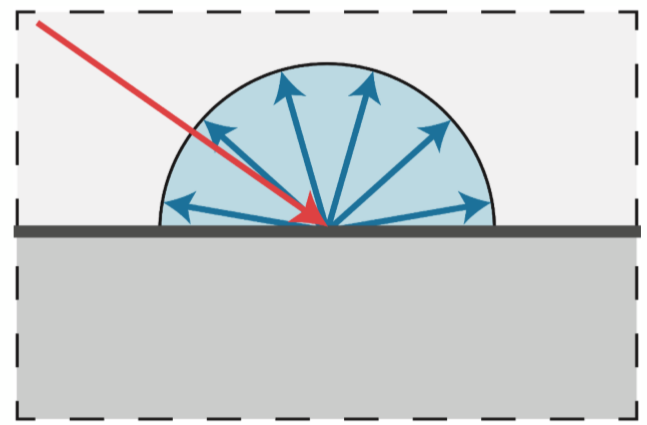
那影响漫反射光照强度的因素有哪些呢?
- 入射光线与法线的夹角(入射光线角度)
- 入射光线自身的强度
入射光线与法线的夹角
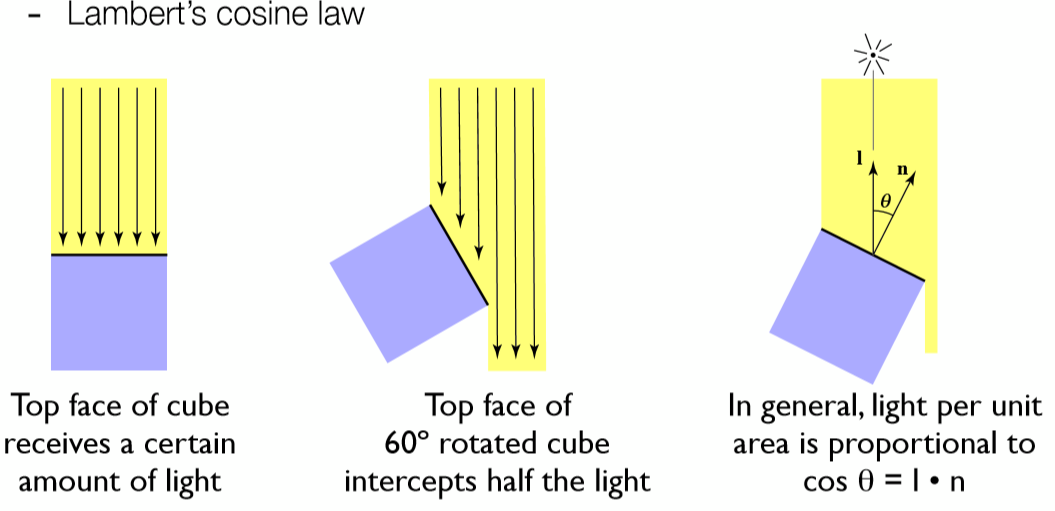
从图中可以明显看出:只有当入射光线与平面垂直的时候才能完整的接受所有光的能量,而入射角度越倾斜,平面接收的光越少,损失的能量越大。定量的来说,应该将光强乘上一个$cos\theta = n⋅l$(因为 $n⋅l=|n|\cdot|l|cos\theta$,而 $n、l$ 为单位向量,长度为1),这样才能正确表示平面所接收的所有光照。
入射光线自身的强度
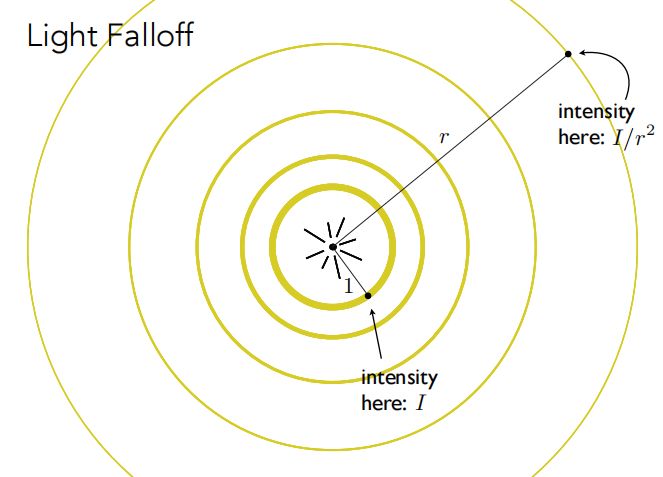
光的强度会随着距离的增加而衰减,这是显而易见的。假设我们有一个光源,在距离它单位1的圆上(图中最内圈)每一个点接收到光的强度是 $I$ 。那么根据能量守恒定律,且不考虑衰减,在距离光源 $r$ 位置的圆上每个点接收到光的强度就是 $\frac{I}{r^2}$ (这里是3D模型,故考虑的是光散射的圆壳的面积)。
至此,我们可以较好的得到漫反射的模型:
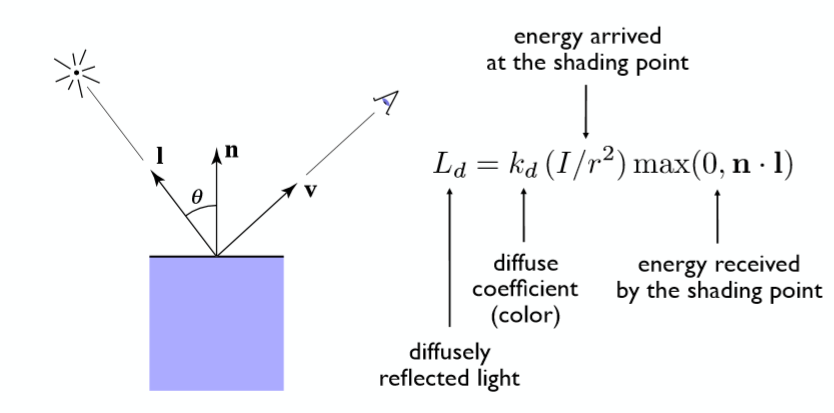
其中 $L_d$为漫反射光照,$k_d$ 为物体表面的反射系数(reflection coefficient),$\frac{I}{r^2}$ 是当前点接受的光照强度,$max(0,n\cdot l)$是当前点接受到的能量。为什么当前接受到的能量要这么表示?试想如果光照从着色点底部入射,那么其与法线的夹角就会大于90°,值会变成负数没有意义,此种情况下我们默认漫反射光照为0。
什么是反射系数 $k_d$ ?
反射系数指光(入射光)投向物体时,其表面反射光的强度与入射光的强度之比值(有多少入射光能够被反射出去,其值介于0~1之间),受入射光的投射角度、强度、波长、物体表面材料的性质以及反射光的测量角度等因素影响。一般来讲,在颜色系列中,黑色的反射系数较小,为0.03,白色的反射系数较大,为0.8。
简要来说,$K_d$与颜色有关,这一点将在下面的部分着重讨论。
同时,我们观察漫反射公式可以发现,漫反射光照与观察方向v没有关系。这是可以理解的,因为漫反射光在任何反射方向上的分布都是一样的,所以无论在哪个方向观测,只要入射光线强度不变、入射光线与法线夹角不变,漫反射光照均相同。
镜面/高光反射(Specular highlights)
高光反射也称为镜面反射,若物体表面很光滑,当平行入射的光线射到这个物体表面时,仍会平行地向一个方向反射出来。
初中物理知识可以知道,镜面反射知道入射方向和法线方向就可以得到反射方向。如下图中一根入射光线,照射在光滑的平面上,会沿着$R$ 方向反射,由于平面并非完全光滑,所以反射光的方向并非只有$R$ 一个点,而是 $R$ 周边的一小块区域,只要眼睛(摄像机)在 $R$ 附近都可以看得到,越靠近 $R$ 反射光照强度越大。我们可以得出一条结论:高光反射和观察角度有关。
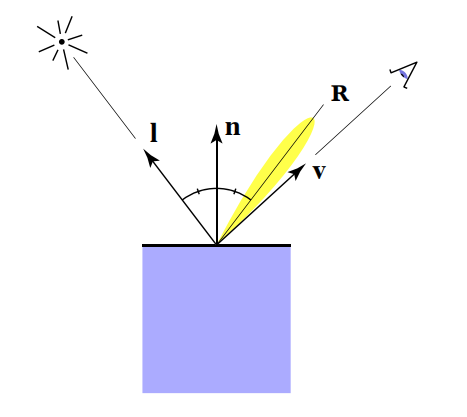
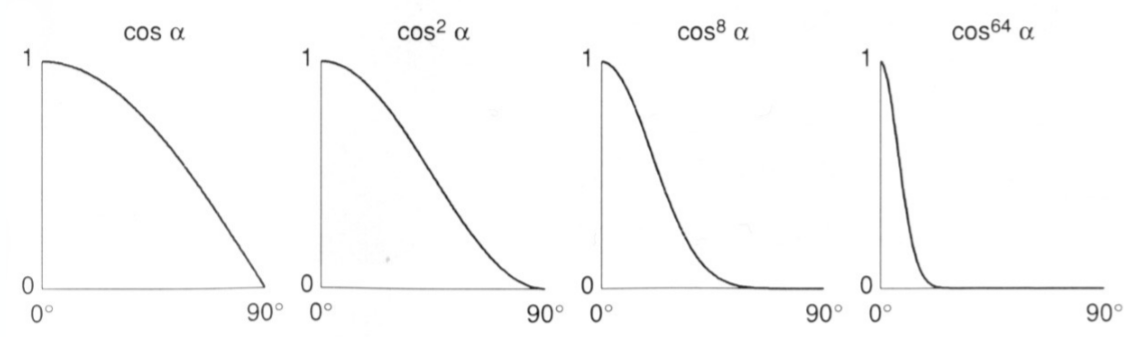
phong模型中认为,高光反射的强度与反射光线 $R$ 和观察角度 $v$ 之间夹角的余弦值成正比。事实上,这个角度是不好求的,如何用简便的方法来近似计算呢?我们可以想象:$l$ 和 $v$ 的平分向量为 $h$ ,当 $v$ 离 $R$ 越近时,$n$ 就离 $h$ 越近,而 $h$ 是十分好求的,即向量 $l$ 和 $v$ 之和的单位方向向量,我们称之为半程向量,数量表示为:
$$
h = bisector(v,l)=\frac{v+l}{||v+l||}
$$
图示为:
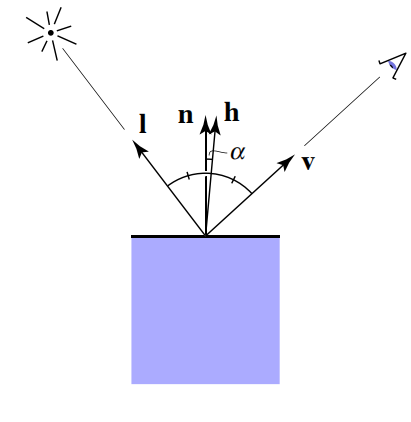
至此,我们得到了镜面反射的数值表示:
$$
L_s=k_s(\frac{I}{r^2})max(0,cos\alpha)^p=k_s(\frac{I}{r^2})max(0,v \cdot R)^p=k_s(\frac{I}{r^2})max(0,n\cdot h)^p
$$
其中 $k_s$ 为镜面反射系数,$\frac{I}{r^2}$ 是当前点接受的光照强度,注意这里在max剔除大于90°的光之后,我们还乘了一个指数 $p$,添加该项的原因很直接,高光对于夹角的度数是十分敏感的,换句话说,只要观察方向稍微偏离反射方向,高光就会剧烈衰减,所以需要一个指数 $p$加速衰减,$p$ 越大,高光越小越聚集。图示可以明显看出 $p$ 对于加速高光衰减的效果。另外严格意义上说,镜面反射仍有接受光照能量的损失,在此为了简化不做考虑。
下图中许多小球,展示了反射系数和 $p$ 值变动对高光反射效果的影响:

环境光(Ambient lighting)
环境光也称间接光,是光线经过周围环境表面多次反射后形成的,利用它可以描述一块区域的亮度,在光照模型中,通常用一个常量来表示。
$$
L_a = K_aI_a
$$
其中 $K_a$ 代表物体表面对环境光的反射率,$I_a$ 代表入射环境光的亮度,$L_{a}$ 表示人眼所能看到从物体表面反射的环境光的亮度。
总结
至此,我们得到了Blinn-phong 光照模型的三个光照要素,整体的计算公式为:

重心坐标(Barycentric Coordinates)
本节不是在讨论着色吗,为什么会突然牵扯到重心坐标?
事实上,重心坐标对于求三角形内部的插值用于着色,以及对之后的纹理映射都是十分有帮助的。
定义及说明
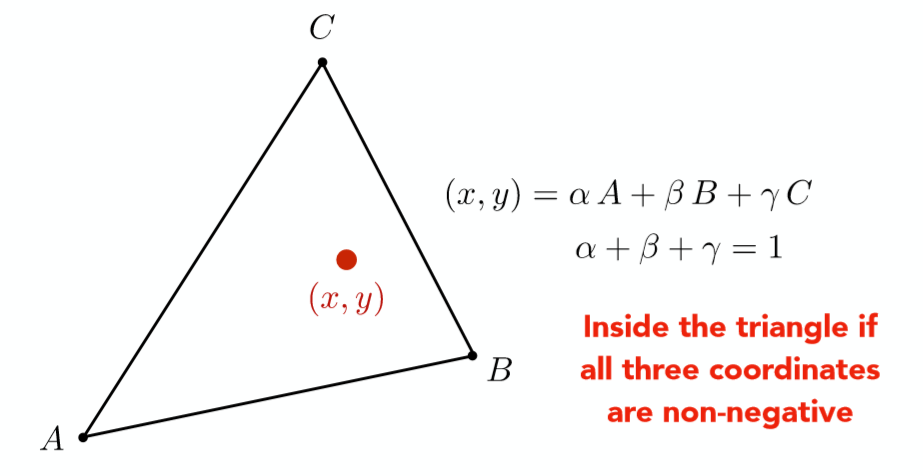
给定三角形的三点坐标 $A, B, C$ ,该平面内一点 $(x,y)$ 可以写成这三点坐标的线性组合形式,即 $(x,y) = \alpha A+\beta B+ \gamma C$ 且满足 $\alpha + \beta + \gamma=1$ ,则称此时3个坐标 $A,B,C$的权重 $\alpha, \beta ,\gamma$ 为点 $(x,y)$ 的重心坐标。特别的,三角形重心的重心坐标为$(\frac{1}{3},\frac{1}{3},\frac{1}{3})$。
说明:我们要保证 $\alpha, \beta ,\gamma$ 是非负的,这样才能确保点与三角形在同一平面内,而 $\alpha + \beta + \gamma=1$ 是为了确保点在三角形内。这都是数学上的正确定义,在此不做深究。
运用上述公式我们并不能计算出一个点具体的重心坐标。如何定量呢?
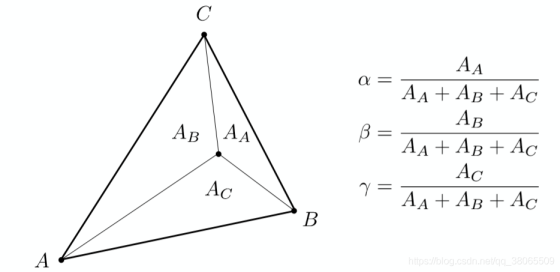
将一点 $(x,y)$ 与 $A,B,C$ 三点直接连接,构成三个三角形面积分别为 $A_A,A_B,A_C$ ,即可直接定义出重心坐标如图中公式所示。根据这条定义,我们只需求出各个三角形的面积便可以直接得出重心坐标了!
其实面积也是比较难算的,我们可以通过所求点和顶点的坐标等式转换为下面这个式子来求重心坐标(这仍是数学问题,不做深究):
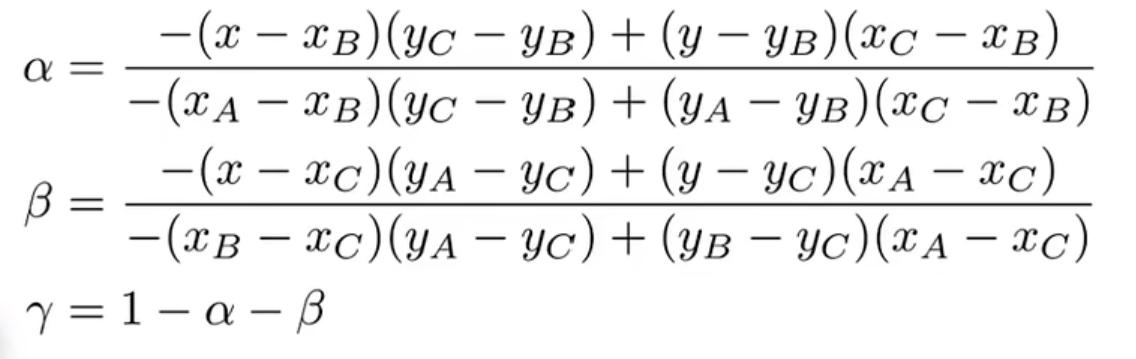
运用
重心坐标在图形学中最重要的运用便是插值,它可以根据三个顶点 $A,B,C$的属性插值出任意点的属性,无论是位置,颜色,深度,法线向量等等,而这些属性在之后的着色或是消除隐藏曲面都有很大的作用。它还可以在处理光栅化问题中判断一个点是否在三角形内,利用重心坐标是否都大于0来代替之前的叉乘(其实二者一定程度上是等价的)。利用该条件来进行sample再判断是否画出该像素。
着色方法/频率(shading frequency)
上述光照模型主要利用了观察方向,入射光线与法线向量的位置关系进行公式上的推导。其中对于“着色点”(即引出法线的那个点)我们并没有过分强调,但这其实是十分重要的。“着色点”可以是一个面,也可以是顶点,也可以是像素,我们都可以对对应的“着色点”进行着色,如下图:

在图形学中,我们称之为着色频率(面着色,顶点着色,像素着色),这3种不同的着色频率其实也就对应了三种不同方法。
面着色(Flat Shading)
面着色,顾名思义以每一个面作为一个着色单位。前面我们说过三角形是最基础的多边形,所以实际模型数据中大多以很多个三角面进行存储,因此也就记录了每个三角形面的法线向量,利用每个面的法线向量进行一次Blinn-Phong反射光照模型的计算,将该颜色赋予整个面至整个物体,效果如下:

Flat Shading 虽然计算很快,只需对每一个面进行一次着色计算,但是效果确是很差的,可以很明显的看到一块块面形状,因此不适用于光滑的物体平面。但当物体被细分成无数多的小三角形时,也会有较好的着色效果。
顶点着色(Gouraud Shading)
Gouraud Shading会对每个三角形的顶点进行一次着色。我们只能容易得到每个面的法线向量,如何得到每个顶点的法线向量呢。做法其实很简单,将所有共享这个点的面的法线向量加起来求均值,最后再标准化就得到了该顶点的法线向量了。有了每个三角形的顶点向量之后,自然就可以计算出每个顶点的颜色了,那么对于三角形内部的每一个点应该怎么办呢(在面着色中,整个面都是同样的着色,所成的效果显然不好。而在点着色中,我们期望从三角形顶点到顶点之间内部呈现一个颜色渐变的状态,更自然也更符合常理)?对,就是利用上述所提到了重心坐标来插值了!公式如下:
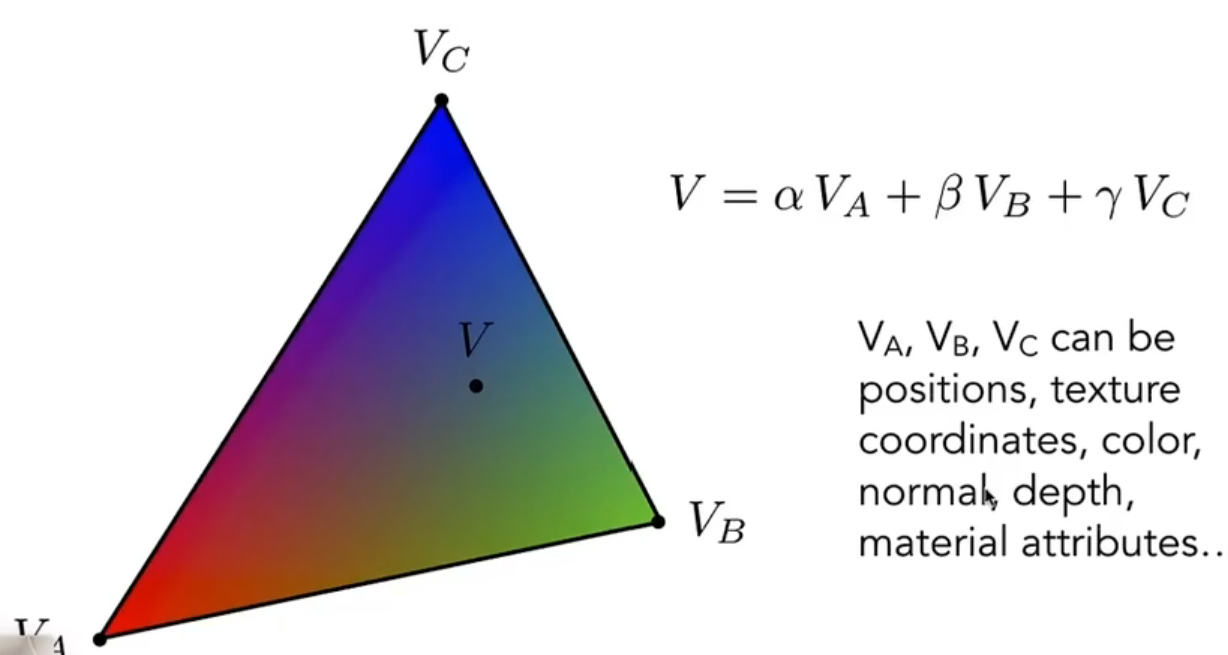
其中$V_A,V_B,V_C$ 代表三个顶点的颜色,$V$ 代表当前所求点, $\alpha, \beta ,\gamma$ 为点 $V$ 的重心坐标,我们只需将重心坐标与顶点颜色进行加权的相加计算即可得到所求点应该的颜色。
整体效果如下:

可以明显看出相对于Flat Shading,Gouraud Shading的效果有着明显的提升,但这样依然还不是最好的做法,因为我们实际上只对每个三角形顶点进行了着色,然后其它的颜色都是通过插值得到,有没有一种做法可以真正的对每个点用Blinn-Phong模型计算得出颜色呢?
像素着色(Phong Shading)
Phong Shading的做法其实也是很好理解的,既然要对每个点都进行光照计算,那么自然我们应该要有每个点的法线向量才可以。上述提到了如何得到每个顶点的法线向量,那么对于三角形内部的每一个点的法线向量自然也可以像插值颜色一般得到:
$$
n = \alpha n_0+\beta n_1+ \gamma n_2
$$
其中 $n_0,n_1,n_2$ 分别是三角形三个顶点的法线向量,$\alpha,\beta,\gamma$ 为三角形面内一点的重心坐标,$n$ 为该点插值之后得到的法线向量。如此便得到了任意一点的法线向量了,也当然可以对任意一点进行Blinn-Phong模型的计算了。最终渲染效果如下:

可以明显看出Phong Shading对于高光的显示相比于Gouraud Shading是更真实的。
模型精度的提升,各种shading type又会有怎样的区别呢:

图形/实时渲染管线(Graphics/Real time Pipeline)
所谓图形/实时渲染管线指的是一系列操作的流程,这个流程具体来说就是将一堆具有三维几何信息的数据点最终转换到二维屏幕空间的像素。其实也就是将之前的所有知识连贯起来。以如下图作为一个总结,再具体分步骤讲解:
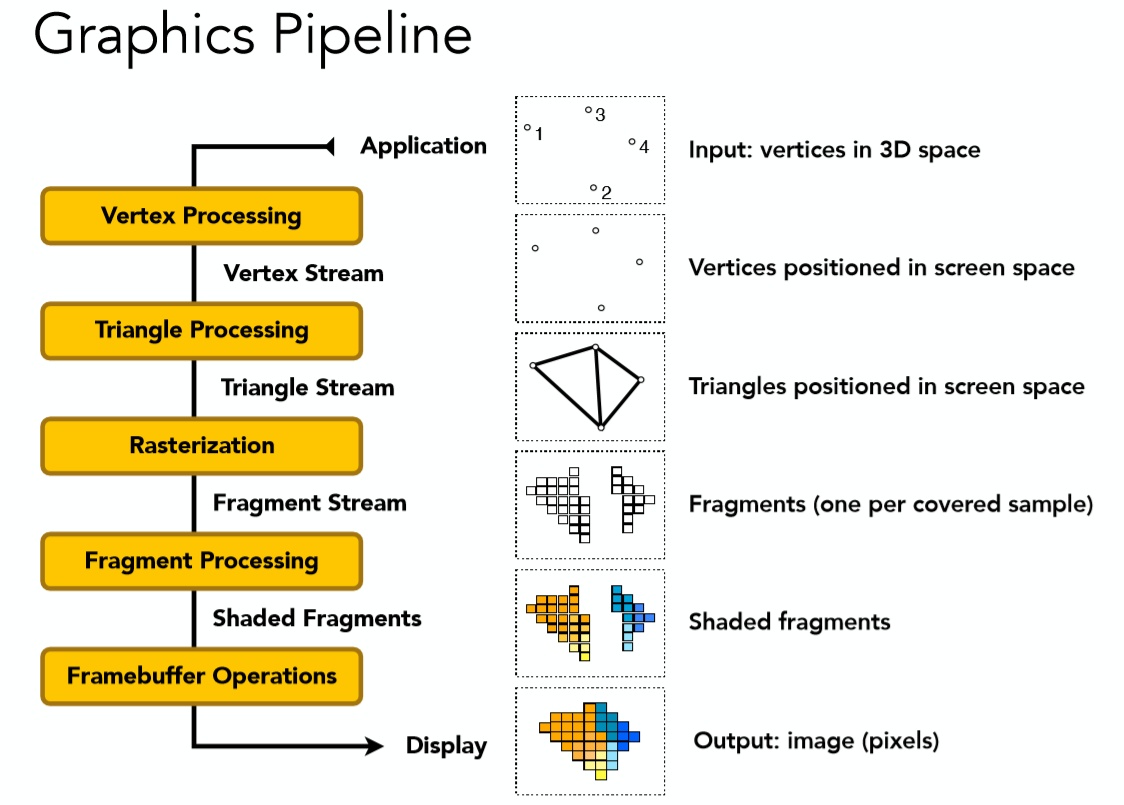
首先来看第一个,顶点处理:
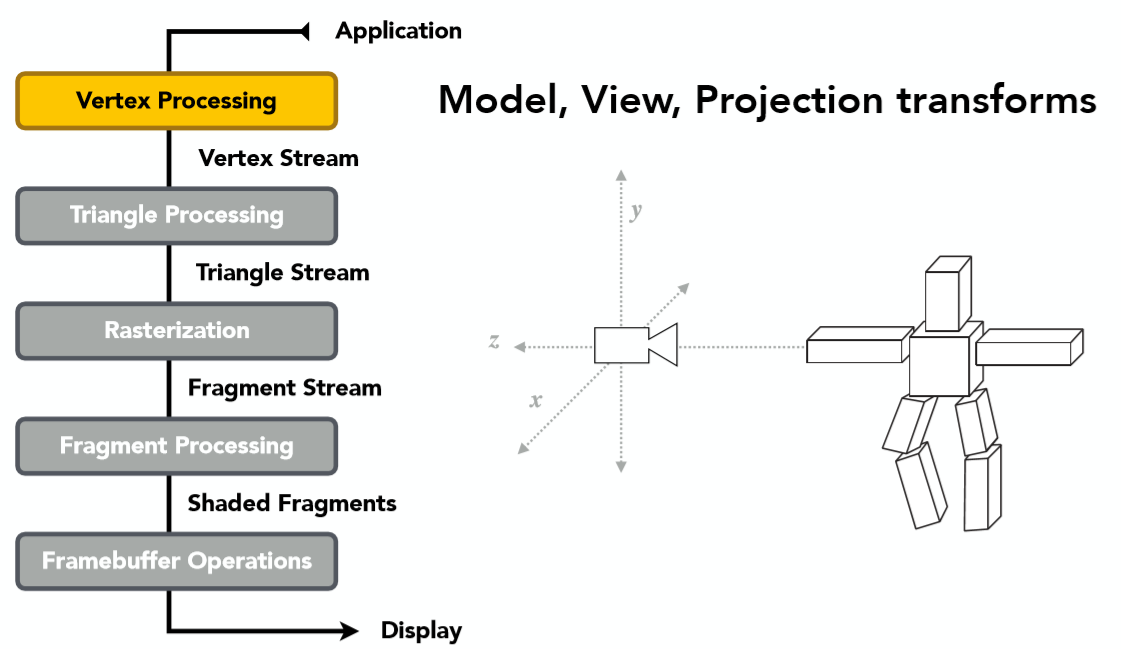
顶点处理的作用是指对所有的顶点数据进行Model,View和Projection(MVP)的变换,最终得到投影到二维平面的坐标信息(同时为了Zbuffer保留深度z)。
而第二步三角形处理也十分容易理解,就是将所有的顶点按照原几何信息,变成三角面,每个面由3个顶点组成。得到了许许多多个三角形之后,接下来的操作自然就是三角形光栅化了:
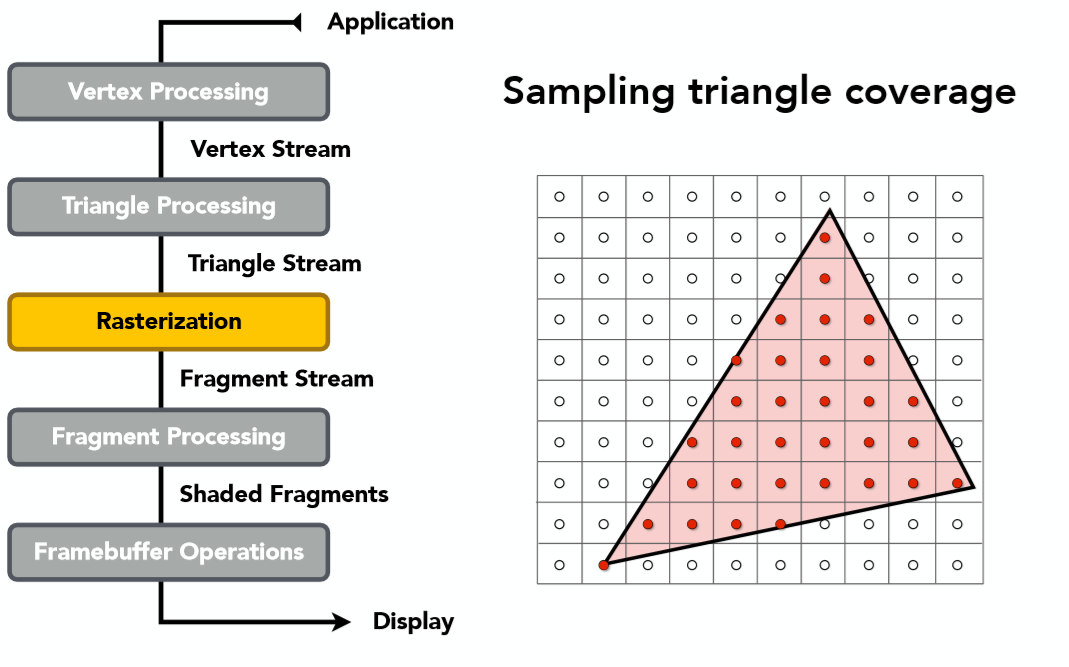
在进行完三角形的光栅化之后,知道了哪些在三角形内的点可以被显示,那么如何确定每个像素点或者说片元(Fragement)的颜色呢?
自然是着色了,也就是片元处理阶段应该做的:
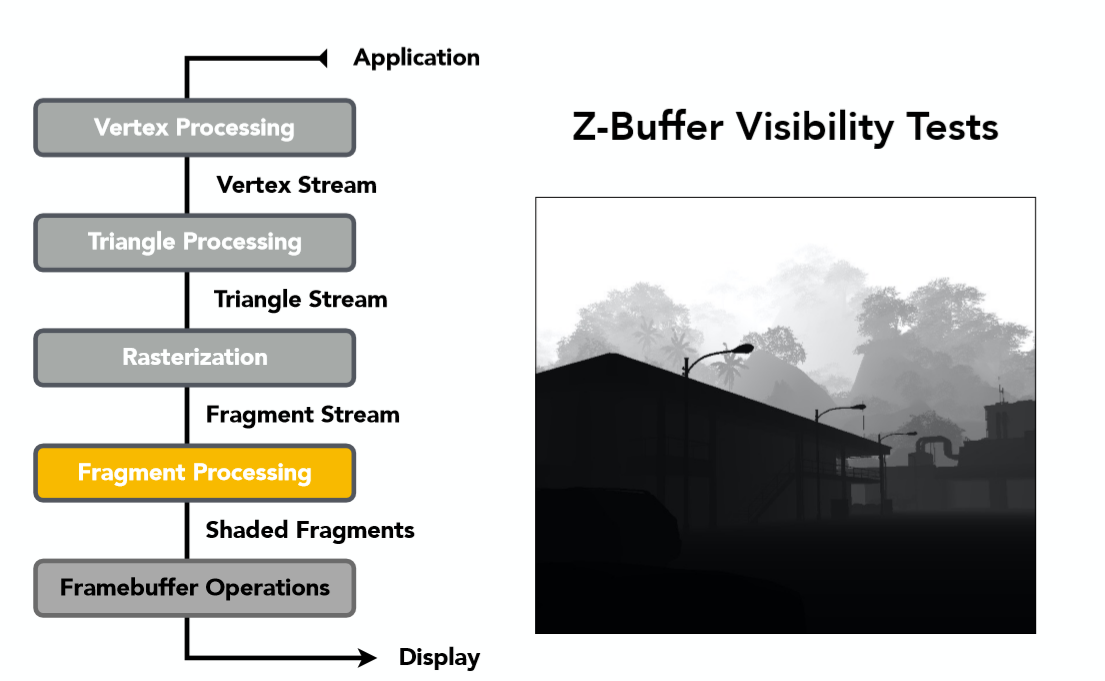
注意这阶段顶点处理也亮起来是因为我们需要顶点信息对三角形内的点进行属性插值(tips:当然也可以直接在顶点处理阶段就算出每个顶点的颜色值,如Gouraud Shading一样)。当然这一阶段也少不了Z-Buffer来帮助确定,哪些像素点应该显示在屏幕上,哪些点被遮挡了不应该显示:
最后一步Framebuffer的处理,就是将所有的像素颜色信息整合在一起,输送给显示设备加以显示。这也就完成了整个图形渲染管线了。
shader
shader称作着色器,分为顶点着色器(vertex shader)以及片元/像素着色器(fragment/pixel shader),主要用于上述渲染管线的 vertex processing阶段以及fragment processing阶段,程序员可以自行编程来代替原来固定的顶点处理和片元处理从而达到各种各样令人惊叹的效果!这也就是现在的可编程渲染管线。
一个简单的像素着色器的 phong模型漫反射:
uniform sampler2D myTexture; //全局变量 纹理
uniform vec3 lightDir; //全局变量 光照方向
varying vec2 uv; //纹理图坐标
varying vec3 norm; //每个着色点法线坐标
void diffuseShader(){
vec3 kd; //漫反射系数
kd = texture2d(myTexture, uv); //通过纹理图找到每个点的漫反射系数
kd *= clamp(dot(-lightDir, norm), 0.0, 1.0); //计算漫反射光照
gl FragColor = vec4(kd, 1.0); //返回值
}纹理映射(Texture Mapping)
先来观察这么一张图:

无论是球上的图案,以及地板的木头纹理都呈现出了不同的颜色信息,那么回想在讲解Blinn-Phong反射模型的时候曾提到,一个点的颜色是由其漫反射系数决定的,反射什么颜色的光,人眼就能看见什么颜色。针对上面这幅图,难道要去对每一个点自己去设定一个颜色吗?
我们可以将三维物体上的任意一个点都映射到一个2维平面之上,再来看一个地球仪的例子:
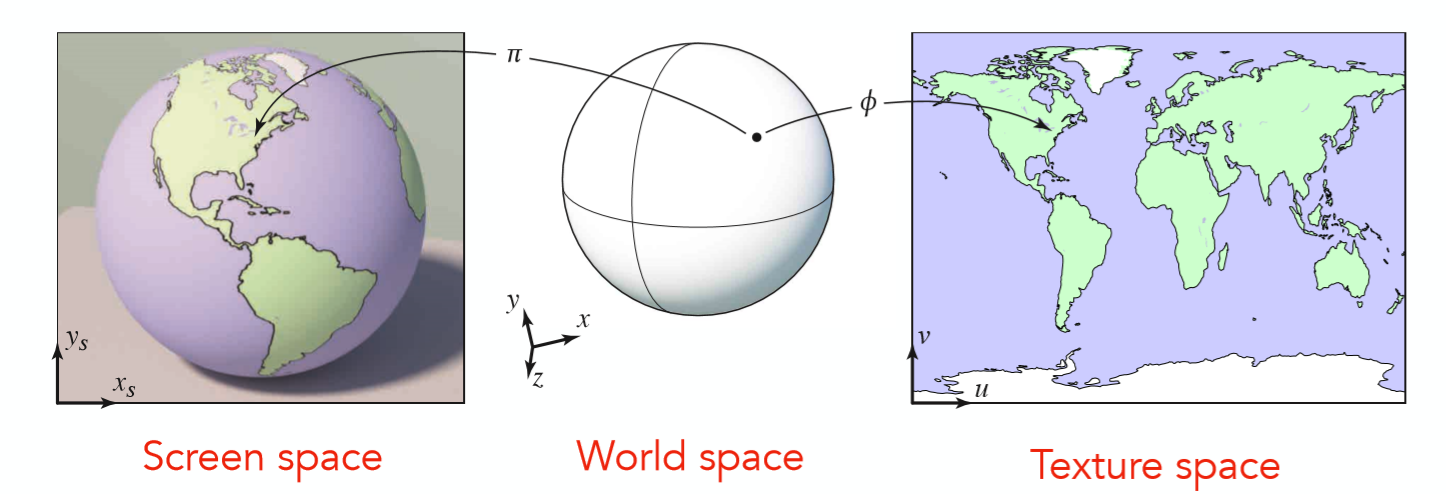
倘若拥有从3维World space到2维Texture space的一个映射关系,那么只需要将每个点的颜色信息即漫反射系数存储在2维的Texture之上,每次利用光照模型进行计算的时候根据映射关系就能查到这个点的漫反射系数是多少,所有点计算完之后,结果就像最左边的screen space之中,整个Texture被贴在了模型之上。
以下是百科对纹理映射的解释:
纹理映射(Texture Mapping),又称纹理贴图,是将纹理空间中的纹理像素映射到屏幕空间中的像素的过程。简单来说,就是把一幅图像贴到三维物体的表面上来增强真实感,可以和光照计算、图像混合等技术结合起来形成许多非常漂亮的效果。
有了Texture,有了映射关系,对渲染结果会有一个非常大提升,因为很多fancy的效果都可以通过texture的设计得到(当然这属于美术的活儿了,咱们用就行了)。来看一个独眼巨人:
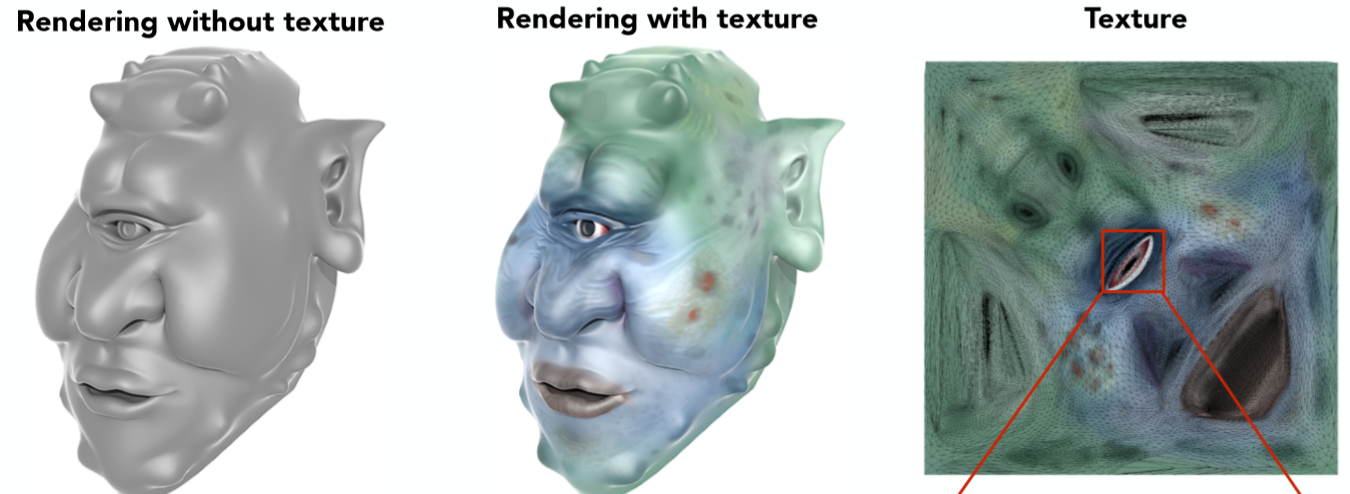
通过将 texture 贴到独眼巨人模型上,可见它更加生动形象了(更丑了…)
到目前为止,我们考虑一下做了些什么:在将物体光栅化映射到二维屏幕之后,需要考虑着色问题,我们运用 Blinn-phong 光照模型对每一个像素进行着色,如何考虑着色过程中的漫反射系数,就是通过纹理映射得到。确切的说,纹理映射不仅仅是用来得到漫反射系数的,可以通过它得到着色点的各个属性。
那么有了一张Texture之后,这种纹理到模型的映射关系究竟是如何表示的呢?这就要从纹理坐标 $(UV)$ 说起了。在纹理空间之内任意一个二维坐标都在 $[0,1]$ 之内。如下图是一个可视化纹理坐标的结果:
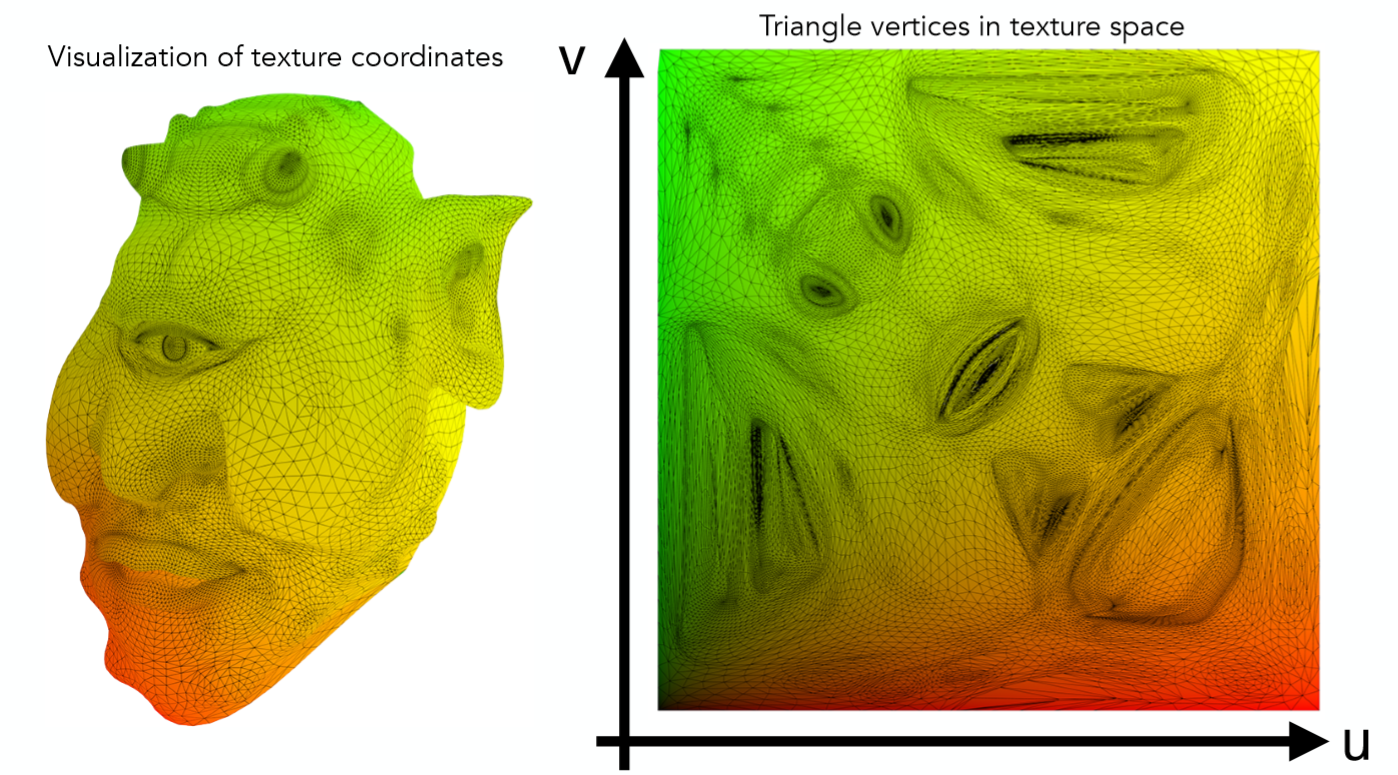
横轴和纵轴的最大值都为1,一幅Texture上的任意一点都可以用一个 $(u,v)$ 坐标来表示 $(0<=u<=1,0<=v<=1)$,因此只需要在三维world space中每个顶点的信息之中存储下该顶点在texture space的 $(u,v)$ 坐标信息,自然而然的就直接的得到了这种映射关系。
一个纹理坐标使用的伪代码供参考:
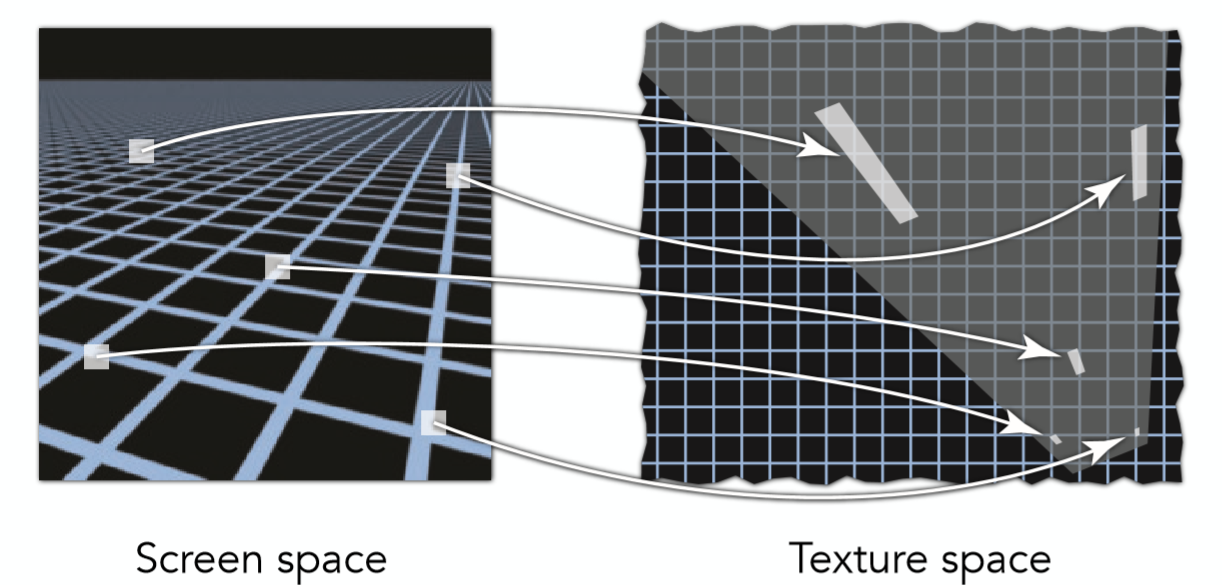
简而言之就是对每个光栅化的屏幕坐标算出它的 $uv$ 坐标(利用三角形顶点重心坐标插值),再利用这个 $uv$ 坐标去查询 texture上的颜色,把这个颜色信息当作漫反射系数 $K_d$。
纹理过小带来的问题
纹理过小的问题相对容易理解,想想我们把一张 $100100$ 的纹理贴图应用在一 $500500$ 的屏幕之上,必然要对纹理进行方法,这就会导致走样失真,因为屏幕空间的几个像素点对应在纹理贴图的坐标上都是集中在一个像素大小之内。那么如果仅仅是使用对应 $(u,v)$ 坐标在texture贴图下最近的那个像素点,往往会造成严重的走样。
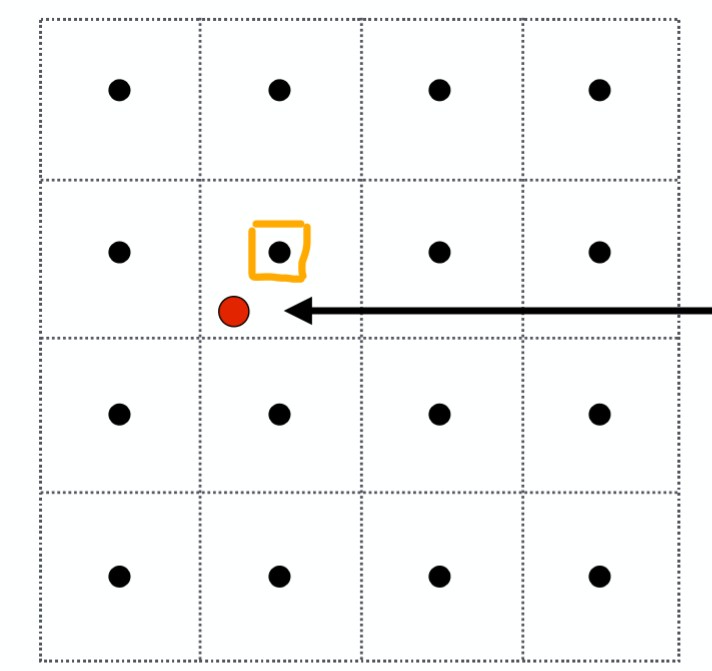
如图中红色点是屏幕空间下一像素所对应在texture空间中的点,因为它没有精确的对应 texture 中的像素点,如果去选择离它最近的那个橙色框起来的点,那必然会导致走样。如下图:

双线性插值(Bilinear Interpolation)
如何改善走样?利用双线性插值。
我们依然取上图的点作为例子。第一步,取出离红色点最近的4个黑色顶点,分别算出该红色点在水平及竖直方向偏移的比率 $s,t$,图示如下:
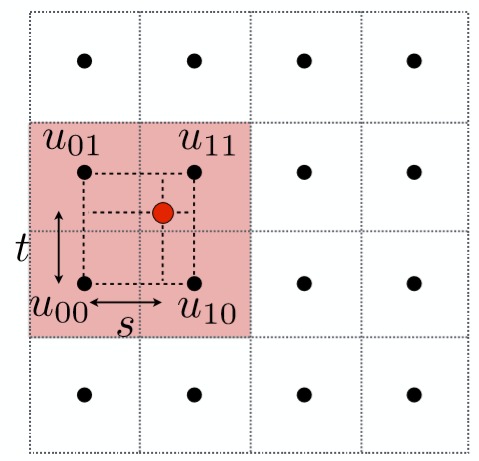
接着先利用 $s$,可以线性插值出如下图所示的 $u_0,u_1$ 点的颜色值:

接着利用 $t$ ,颜色值 $u_0,u_1$ 插值出红色点的颜色值:
$$
f(x,y)=lerp(t,u_0,u_1)
$$
如此这样利用两次线性插值,综合考虑到了所有4个点的颜色值,能够很好的缓解走样失真现象,并且计算速度较高。效果如图:

纹理过大带来的问题
可能对于我们的第一直觉来说,纹理小确实会引发问题,但是纹理大那不是更好吗,为什么会引发问题呢?但事实是纹理过大所引发的走样甚至会更加严重。想象一张很大的地板,在上面铺满了重复的方格贴图,我们所期望看到的结果应该是这样的:

这符合透视投影近大远小,不过这是标准答案。如果此时纹理过大,采用采样着色之后的效果是这样的:

不堪入目,近处锯齿,远处摩尔纹,非常严重的走样现象,为什么会导致这样的一个现象呢?这是我的理解:
地板上铺满了重复的方格贴图,根据近大远小,远处的一张完整的贴图可能在屏幕空间中仅仅是几个像素的大小,那么必然屏幕空间的一个像素对应了纹理贴图上的一片范围的点,这其实就是纹理过大所导致的,直观来说想用一个点采样的结果代替纹理空间一片范围的颜色信息,必然会导致严重走样!就是前面所说的采样导致的走样本质:采样频率跟不上信号频率
(tips:为什么1个屏幕空间像素点覆盖多个纹理空间像素就是纹理过大呢,想象一下纹理贴图大小 $500500$,屏幕空间 $100100$,将屏幕空间的像素点均匀分布在纹理空间之中,那么1个屏幕空间像素点所占的平均大小就是 $5*5=25$ 个纹理空间像素,因此这就是纹理过大所导致的结果)
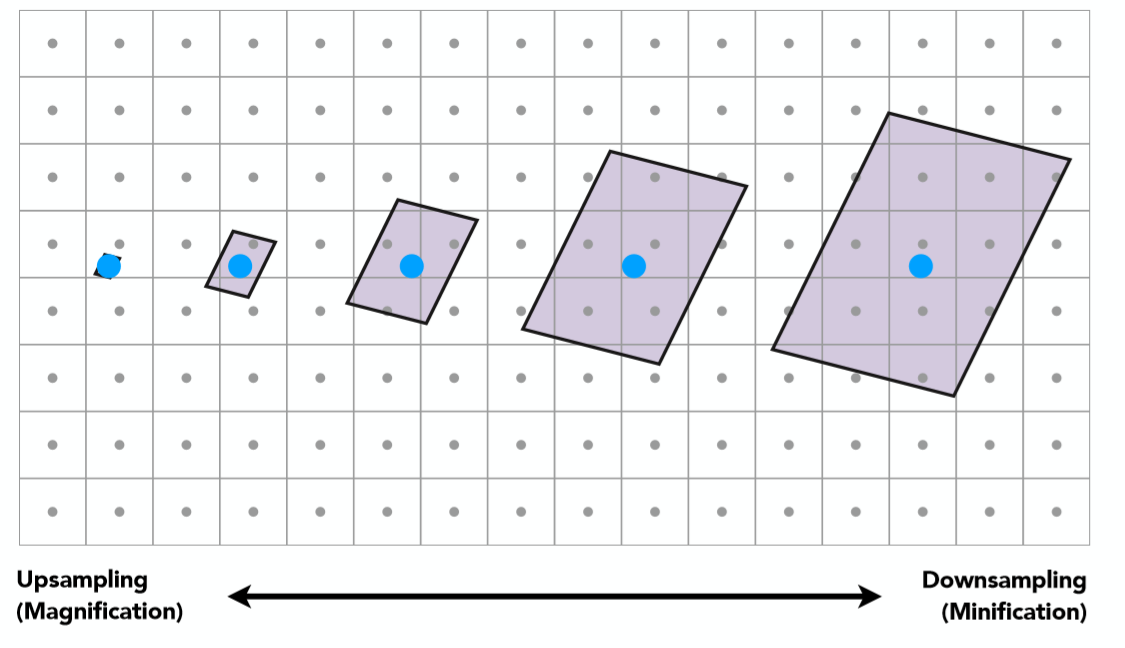
上图就是一个很好的例子,一个屏幕空间的蓝色像素点离相机越远,对应在texture空间的范围也就越大。其实也就是越来越缺少采样,那么一种直观的解决方法就是 Supersampling,如果一个像素点不足以代表一个区域的颜色信息,那么便把一个像素细分为更多个小的采样点不就可以解决这个问题了吗?确实是这样,可以看看如下图超采样的结果:

效果虽称不上完美但也极大缓解了走样现象,但问题是什么?计算量太大了,一个像素点被分为了 $512*512$ 个采样点,计算量几乎多出了25万倍!这显然不是所希望看到的。换一种想法,如果不去超采样,仅仅是求出每个屏幕像素里所有texels的颜色均值呢?
Mipmap
正如上文所提,一个采样点的颜色信息不足以代表 texture 里一个区域的颜色信息,如果可以求出这样一个区域里面所有颜色的均值,是不是就是一种可行的方法呢?没错,我们的目标就是从点查询 Point Query 迈向区域查询 Range Query。但依然存在一个问题,不同的屏幕像素所对应的纹理区域是不一样大小的,即离相机远的像素点必然会对应很大一片纹理区域,看下图这样一个例子:

远处圆圈里的对应的纹理区域必然比近处的要大,因此必须要准备不同等级(level)的区域查询才可以,而这正是Mipmap。
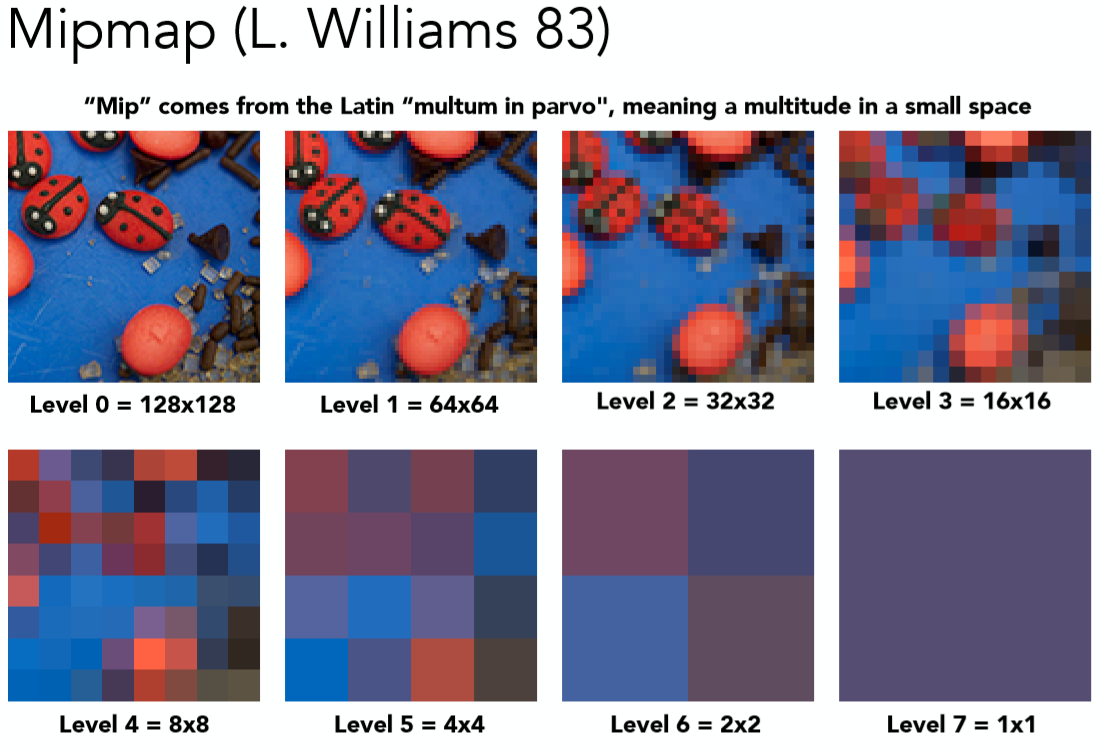
Level 0代表的是原始 texture,也是精度最高的纹理,随着 Level 的提升,每提升一级将4个相邻像素点求均值合为一个像素点,因此越高的 Level 也就代表了更大的纹理的区域查询。接下来要做的就是根据屏幕像素的大小选定不同 Level 的 texture,再进行点查询即可,而这其实就相当于在原始texture上进行了区域查询!
那么如何去确定使用哪个 Level 的 texture呢?利用屏幕像素的相邻像素点估算纹理大小再确定 Level 。如下图:
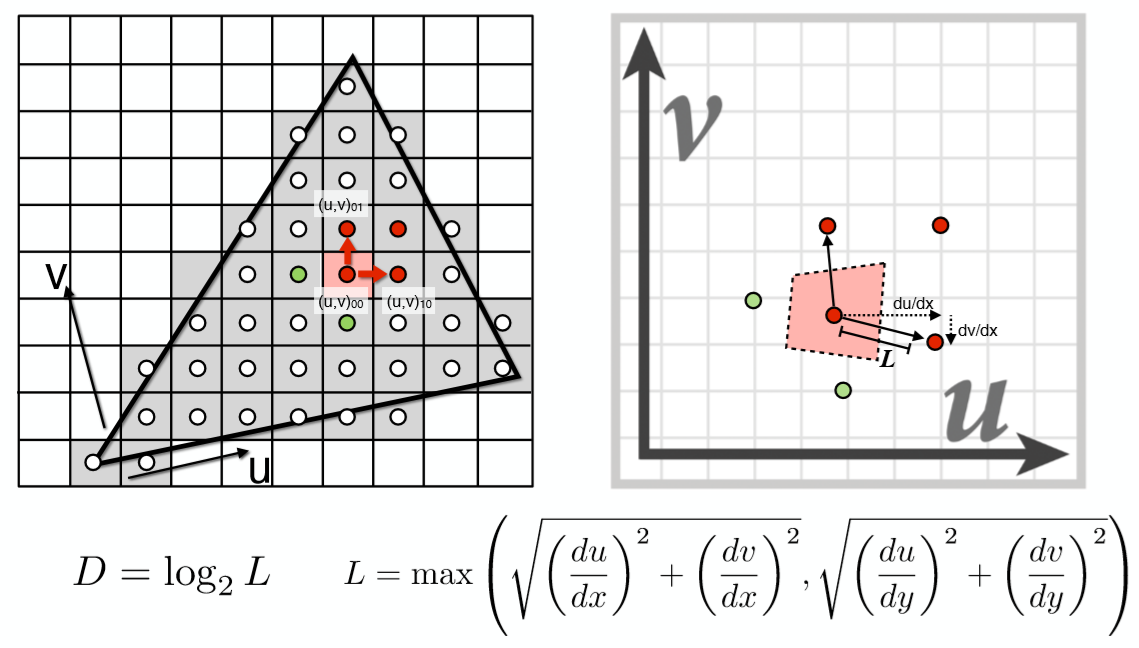
在屏幕空间中取当前像素点的右方和上方的两个相邻像素点(4个全取也可以),分别查询得到这3个点对应在Texture space的坐标,计算出当前像素点与右方像素点和上方像素点在Texture space的距离,二者取最大值,计算公式如图中所示。那么 Level D就是这个距离的$log_2$值 ($ D = log_2L$) 。这不难理解,可以具体取几个例子比如L = 1,L = 2,L = 4,看看是否符合这样的计算即可。
但是这里D值算出来是一个连续值,并不是一个整数,有两种对应的方法:
1. 四舍五入取得最近的那个Level D
2. 利用D值在向下和向上取整的两个不同 Level 进行3线性插值
第一个方法很容易理解,具体讲述一下第二个方法,如图:
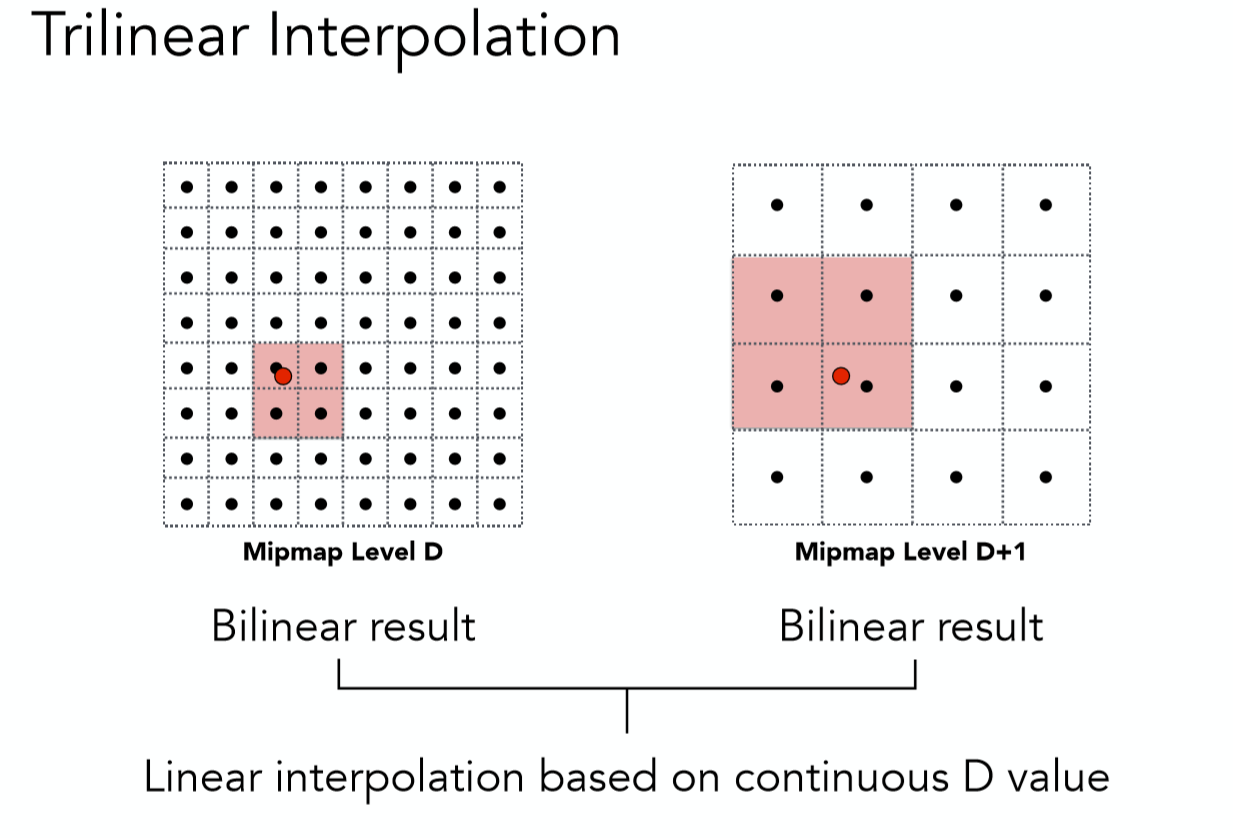
所谓3线性插值,就是在向下取整的 Level D上进行一次双线性插值(前文提过),再在 Level D+1之上进行一次双线性插值,这二者数据再根据实际的连续D值在向下和向上取整的两个不同 Level 之间的比例,再来一次线性插值,而这整体就是一个三线性插值了。
根据上述的方法算出屏幕上每一个像素点所对应的Mipmap level,再进行三线性插值得到颜色值,是否就能很好的解决走样问题了呢?很遗憾,在本文的那个地板的例子之中,费了这么大力气依然不能完美解决,如下图结果:
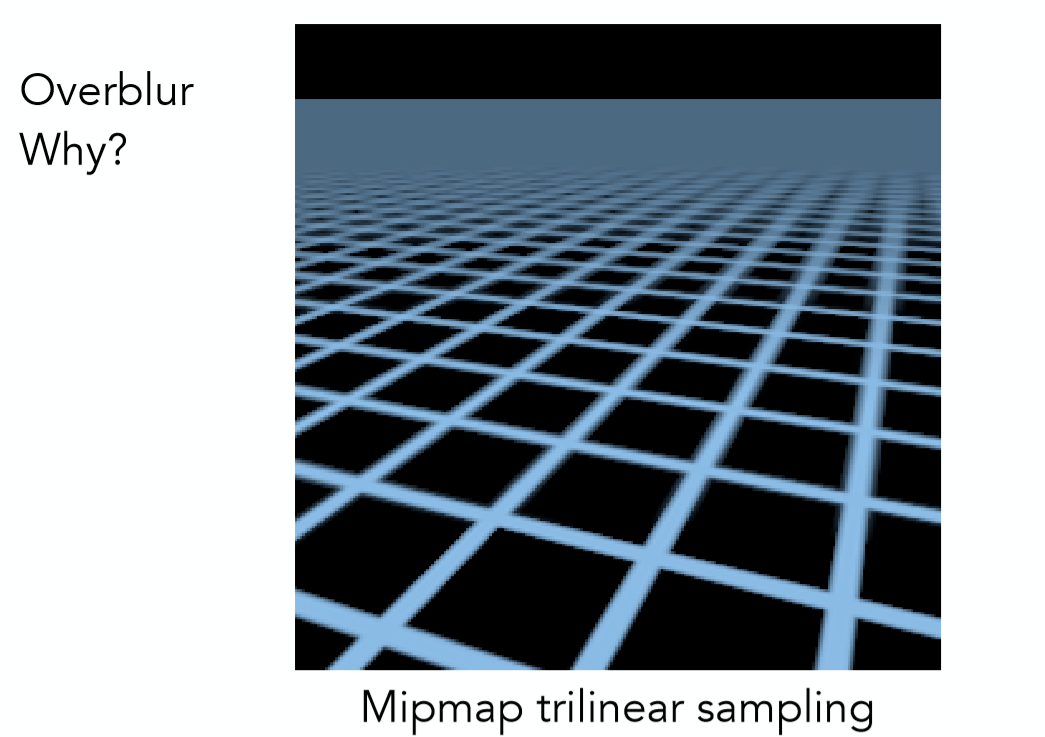
虽然和一开始的 point sample有了很大的进步,但是有一个严重的问题是,远处的地板产生一种过曝的现象,完全糊在了一起。
利用各向异性优化mipmap
为什么 Mipmap 会出现这种情况:
- Mipmap所规定的区域查询,这个区域必须是正方形,而纹理映射中可不仅仅只有正方形
- 3线性插值本身就含有误差
可以看出不同screen space的像素点所对应的footprint是不同的,有长方形,甚至是不规则图形,那么针对这种情况,有的所需要的是仅仅是水平方向的高 Level,有的需要的仅仅是竖直方向上的高 Level,因此这也就启发了各向异性的过滤来改善Mipmap。
各向异性过滤 (Anisotropic Filtering )是用来过滤、处理当视角变化导致3D物体表面倾斜时造成的纹理错误。传统的双线性和三线性过滤技术都是指“Isotropy”(各向同性)的,其各方向上矢量值是一致的,就像正方形和正方体。

图示来说,Mipmap所求得是上图中对角线的图片,而各向异性是针对长宽进行不同比例的缩放来生成图片,在具体的映射中,需要选择一个最合适的纹理。(这个跟上面的Mipmap一样,所额外需要的存储空间仅增加了原来的 $\frac{1}{3}$ ,故对性能几乎没有影响。打游戏的人应该知道游戏画面设置里有各向异性过滤这个选项,其中的 2x、4x、16x 其实就是所额外生成的贴图数量,由于其仅对内存开销有一定的增加,并不会导致性能上的损失降低帧率,所以打游戏建议把各向异性拉满)
利用这样不同的贴图,更加精细的选择后结果就会明显好很多:

当然这只是一种改善 Mipmap 的方法,并不能真正解决问题。
纹理映射的运用
环境光映射(Environment Map)
顾名思义就是将环境光存储在一个贴图之上。想象这样一个情形,光照离物体的距离十分遥远,因此对于物体上的各个点光照方向几乎没有区别,那么唯一的变量就是人眼所观察的方向了,因此各个方向的光源就可以用一个球体进行存储,即任意一个3D方向,都标志着一个texel:
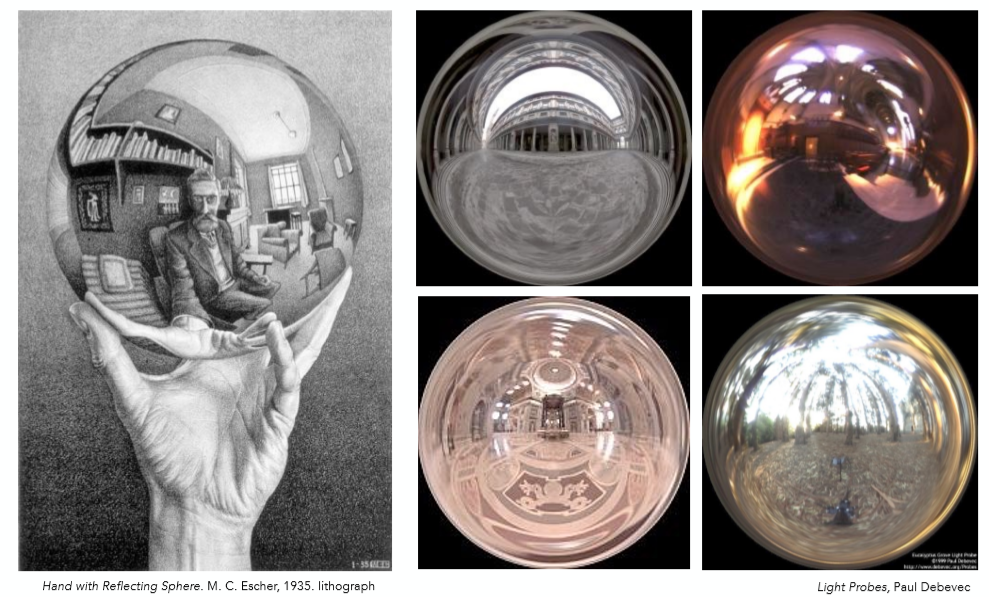
就跟前面的地球仪一样,利用墨卡托投影或是其它类似的方法将球上的信息转换成一个平面上,就得到了环境Texture了:

但是用一个球体来存储环境光有一个比较明显的缺点,仔细观察上面展开的Texture图可以观察看到,上方和下方均有较为严重的扭曲,因此另外一种存储的方法就是Cube Map,也就是天空盒:
一个天空盒有6幅Texture来表示,明显相对球体少了很多扭曲的情况,但是中间多了一步从方向到面上的计算:
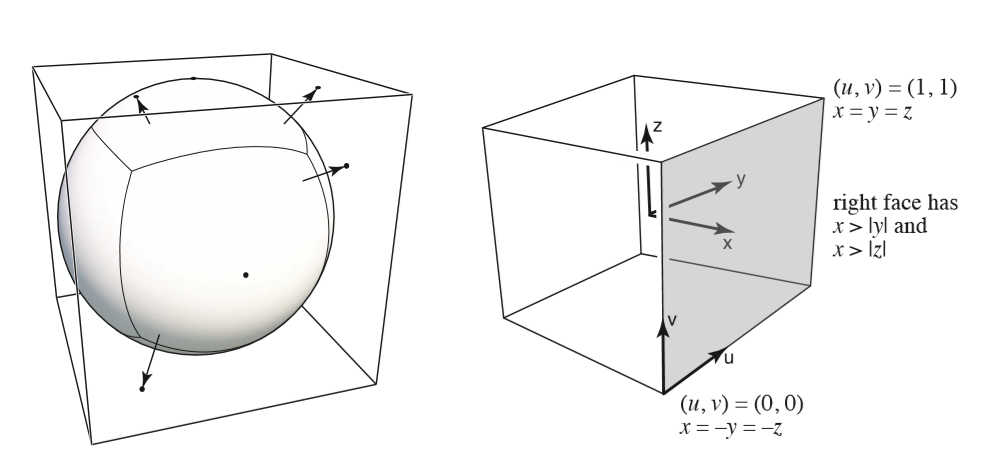
简单来说就是利用球心与球面连线方向计算出与对应平面上的交点坐标,剔除平面所对应的一维,剩下来的两维坐标转换到 $(0,1)$范围之内即为 $(u,v)$ 坐标。一个图例:

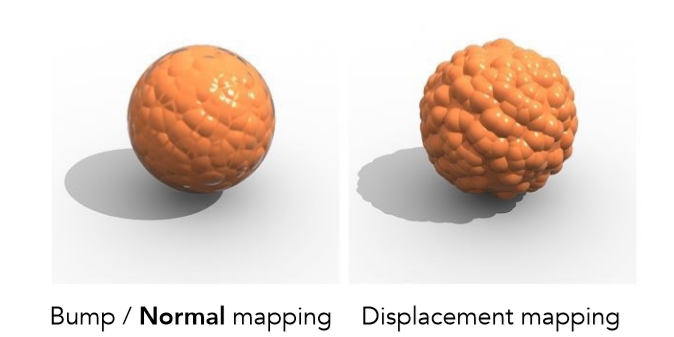
凹凸贴图/法线贴图(Bump/Normal Map)
想向有一个球体,由许多三角形构成。我们想把它修改成一个月球模型,那我们知道月球表面有许多坑坑洼洼的小洞,十分不平整,如何表示这种洞的凹或者丘的凸呢?如果继续采用用许多三角形表示的话,工作量又上了一个台阶。有没有什么好的方法呢?
我们仍然认为所要设计的月球模型内核是一个光滑球体,但是我们可以在纹理贴图上定义每个点的高度进而改变法线向量进而改变shading。Bump/Normal Map就是这种思想,它存储了每一个点逻辑上的相对高度(可为负值),该高度的变化实际上表现了物体表面凹凸不平的特质,利用该高度信息,再计算出该点法线向量,最后再利用该法线计算光照,这就是Bump Map的过程。

那么所需要关心的问题就是,如何从相对高度计算出法线向量呢?

该过程也很容易理解,2维情况如下:
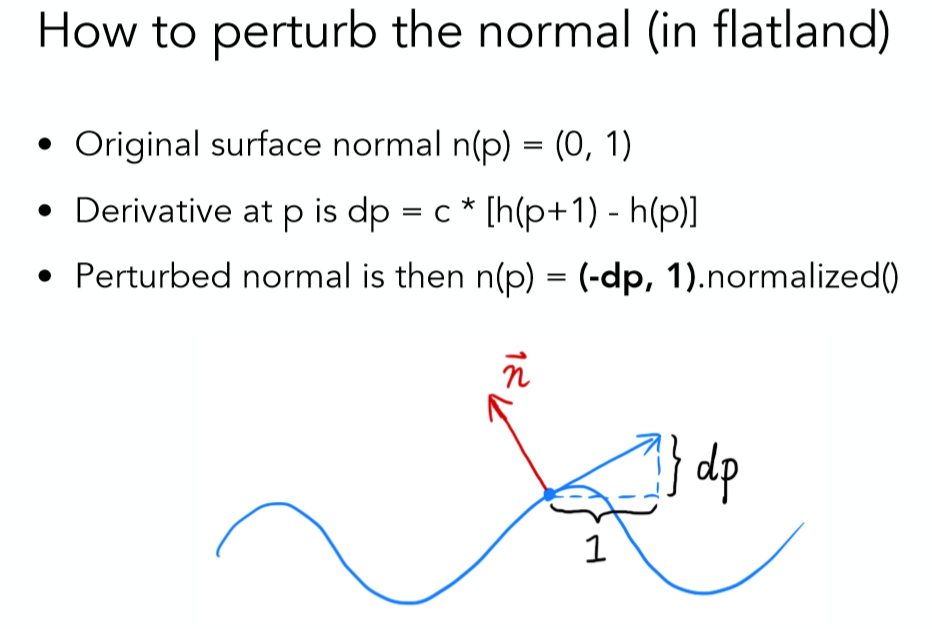
即求一个点的切线之后再逆时针旋转90°求法线。
3维情况可以类推得到:

正如最后一点所标注的,所有计算出来的法线都是局部坐标即切线空间之下,因此还需要左乘 $[t \quad b \quad n ]$ 矩阵转到(世界)相机坐标系之下得到正确法向。
位移贴图(Displacement Map)
Displacement Map其实又与Bump Map十分类似了,出发点都是改变点的相对高度来改变法线。但Bump Maps是逻辑上的高度改变,它实则并没有改变内部的模型,是假的改变;而Displacement Map则是物理上的高度改变,它真正改变了模型。二者的区别就在此处,可以通过物体阴影的边缘发现这点: